

数据中心承载的网络转发数据量越来越大,建设高性能网络势在必行。以往我们将目光都集中在了软件定义网络技术的普及、100G/400G单端口带宽的提升等方面的新技术,而忽略了性能。一个网络的性能高低与每个环节都休戚相关,并不是简单地将网络出口由10G换成40G或100G就能改变的,从流量访问一直到应用软件的处理都需要提升,最大的瓶颈在哪里?
搞过网络技术的人都知道,对于一个交换机,其上的端口能做线速转发是基本要求,但对于服务器来说就很困难,一个1G网卡的服务器,处理流量能达到800M就相当不错了,这是因为服务器收到数据流量还要解析(交换机往往做三层解析就足够,而且是由专门芯片来完成,不消耗CPU资源),将每个报文的内容都要解析出来,然后提供给应用层软件,例如图1:
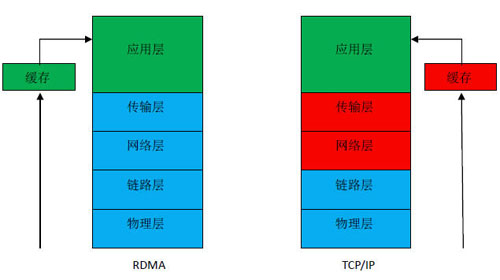
图1:RDMA与TCP/IP技术对比图
图1中右侧是经典的TCP/IP协议,是数据中心内部数据传输网络使用的唯一网络协议,分为五层,其中蓝色标记的代表硬件部分,红色标记的代表是系统软件部分,绿色标记的代表是应用软件部分。在TCP/IP的网络世界里,一个服务器网卡接收到一个数据报文,要经过网络层和传输层,再送给应用层,网络和传输层就要消耗CPU资源,由CPU来查询内存地址,检验CRC,还原TCP包到应用,占用CPU缓存,单位时间内进来的报文数量越多,消耗CPU的资源就越多,CPU除了处理数据报文还要运行其它的应用,CPU并不是完全平稳运行的,CPU的高低波动也会影响处理报文的速度,从而影响网络传输性能。
左侧是RDMA技术,最大的突破是将网络层和传输层放到了硬件中,服务器的网卡上来实现,数据报文进入网卡后,在网卡硬件上就完成四层解析,直接上送到应用层软件,四层解析CPU无需干预,这就是RDMA能带来低延时、高带宽和低CPU利用率的根本原因,也是RDMA技术的吸引人之处。利用RDMA技术,可以将网卡的带宽利用率大幅提升,一个拥有1G网卡的服务器,使用RDMA技术,应用软件处理的数据速度就可以接近1G。服务器可以将几乎100%的CPU 资源都提供给计算,降低了CPU 在网络协议处理中的占用率,服务器可以利用这些CPU 资源来做更多计算或提供其他的服务,相当于增加了虚拟机数量,节省了服务器资源。
RDMA技术的全称叫做Remote Direct Memory Access,即远程直接数据存取,就是为解决网络传输中服务器端数据处理的延迟而产生的。RDMA通过网卡将数据直接传入服务器的存储区,不对操作系统造成任何影响,消除了外部存储器复制和文本交换操作,解放内存带宽和CPU资源。当一个应用执行RDMA读或写请求时,不执行任何数据复制。
在不需要任何内核内存参与的条件下,RDMA请求从运行在用户空间中的应用中发送到本地网卡,然后经过网络传送到远程服务器网卡。RDMA最早专属于Infiniband架构,随着在网络融合大趋势下出现了RoCE(RDMA over Converged Ethernet)和iWARP(RDMA over TCP/IP) ,这使高速、超低延时、极低CPU使用率的RDMA得以部署在目前使用最广泛的数据中心网络上。
随着人工智能和5G网络的兴起,“唤醒万物,万物互联”的时代已经来临。计算量需求的爆发式增长无疑对数据中心的网络提出了更苛刻的要求,需要更多的高性能数据中心。RDMA技术作为一种先进的网络数据传输方式映入眼帘,引起了强烈关注。与传统网络相比,RDMA可更加显著地提升应用效率,提供高性能的网络传输。
RDMA这么好,为什么还没有普及呢,仍只在HPC中有些应用,主要还是价格因素,现如今已经出现了像RoCE这样兼容以太网的技术,相信在数据中心网络领域,RDMA会真正的开花结果,尤其在存储领域,IP存储已经看上了RDMA,很多互联网公司均开始考虑现在存储网络中部署RDMA,然后慢慢向其它网络部分延伸。


